Application Performance Management 101

Introduction
Understanding the importance and benefits of Application Performance Management as a proactive monitoring and remediation tool to detect, locate, diagnose, fix application performance issues.
Background
Monolithic application architectures required any single update to the application to be applied to the whole application stack. Due to the criticality of the application, updates slowed releases and made scaling more problematic.
Problem Statement
The industry moved away from huge, encompassing monolithic applications to distributed applications that assigned the application load across different services. These different service points of analytics can become a complex management nightmare; as a result, making the manual sorting through each data point to determine the location of an issue arduous and time-consuming.
Solution
Application Performance Management detects and diagnoses complex performance issues that allow engineers to determine the location and remediation of a performance bottleneck. AppDynamics is an application intelligence platform that gives IT administrators visibility into the flow of data and real-time insight into application performance, user experience, and business performance impact.
Conclusion
Business applications are the tool that provide business with the information flow internally and with customers to generate sales, maintain customer satisfaction, and increase profitability. Therefore, correcting applications issues becomes a priority if the experience is degraded due to performance problems, application bottlenecks, and other latencies. That is why Application Performance Monitoring and Management are critical as they provide real-time insights into user behavior within the application.
References
Application Performance Management is more important in today’s digital business than ever before. Customer experiences, like online purchases for example, rely on applications to provide rich content and seamless transactions. Repeat customers are the life blood of healthy businesses. Similarly, organizations that rely on complex, distributed, or customized applications need to ensure internal users have reliable and timely access to resources. Issues affecting application availability negatively impact productivity across the enterprise and need to be addressed quickly.
Monitoring applications for issues, bottlenecks, and latencies is one thing; however, companies need more visibility and control of their applications to identify the location of an issue and then remediate it. Monitoring an application’s performance is helpful but it falls short for organizations that need a more precise solution. Application mapping, code-level diagnostics, and dynamic performance baselining to measure the business impact of performance bottlenecks, latencies, and other issues are all elements that require more performance monitoring than ‘normal.’
Ultimately, companies need to implement application performance management (or APM).
But wait, aren’t there two definitions of APM? What exactly is the difference between application performance management and application performance monitoring? In today’s blog post I’ll explain the two ways of defining APM, how a management approach emerged, and then elaborate on why organizations need to implement application performance management. I’ll also cover:
- Application Performance Management from an AppDynamics perspective
- How AppDynamics helps IT teams understand their application infrastructures
- How organizations measure the business impact of performance issues that AppDynamics can provide via common (and custom) dashboards
Defining APM: Application Performance Monitoring vs Application Performance Management
Here’s the difference between the two:
Application Performance Monitoring monitors for performance issues and bottlenecks. Application Performance Management will help businesses monitor and remediate performance issues.
Application Performance Monitoring is more reactive; Application Performance Management is more proactive.
The differences between the two depend on the data streams available in application monitoring. The data streams come from browsers, logs, and monitoring systems. The monitoring systems monitor server CPU, RAM, and storage IOPs. IT teams can parse web server logs to see the number of requests received, the length of time it takes to receive requests, and the error rates inside of the infrastructure. Application owners can view key metrics from dependencies such as SQL, or APIs, or Google Analytics to help them understand how the infrastructure functions, to find slow web sites, and to create alerts. They can also explore other things when monitoring systems. Data streams represent the most important thing IT teams will want to know about and will want to correlate in application performance monitoring and management.
For example, in my lab I built a synthetic transactional monitoring system that uses web scraping. I simulated a customer using a browser and, through code, I could walk through the browser, enter a carting system, look for a specific product, put the product into the cart, and checkout. I used a dummy credit card to make an actual transaction; I then used the workflow to determine the latency between each step of the process. I used Nagios for monitoring the system.
I wanted to learn about the user experience. Nagios provided me visibility into latency and it alerted me about latency being introduced by a flow of user experiences, but it had limitations because it is an alerting mechanism. What would I do with the information I gathered? Was something wrong with the code, the server, or the infrastructure? Ultimately, application owners need to know the source of the bottleneck to solve the performance issues, and for more precise detection and diagnostics they need something more than monitoring. IT teams need Application Performance Management.
Application Performance Management detects and diagnoses complex performance issues that allow engineers to determine the location of a bottleneck and remediate the performance bottleneck. Management includes metrics that help IT teams translate the data into business impact. After all, organizations want to know how performance impacts their business.
The Purpose of Application Performance Management
Two major events impacted the approach to application performance management: application architectures changed, and how we deploy applications changed into DevOps. DevOps is an industry buzzword. It means different things to different people. Nevertheless, the emergence of DevOps impacted the development and deployment of applications for infrastructure teams.
DevOps developed agile methodologies. Agile methodologies consist of a framework for the release of code into the industry, i.e. to enable the movement of application architectures. From this came Continuous Integration and Continuous Deployment (or CI/CD). CI/CD is a set of principles and practices that lets application development teams deliver code changes reliably and quickly. CI/CD automates the software delivery process. DevOps update a subset of the service that is part of an application. That will allow them to move it at a faster pace and release it to market more quickly than in the days when teams only updated monolithic codes.
Application Architectures: Monolithic & Distributed
Teams used to build UI, business logic, and the data access layer into one monolithic application. It was simple but incommodious to deploy and configure. Any single update to the application applied to the whole application. Updates and upgrades impacted the entire stack. That slowed releases and made scaling troublesome because monolithic applications made pinpointing the “where”, “what”, and “how” of issues, bottlenecks, and other impacts much more difficult. Monolithic architectures lacked intelligence and dynamism for DevOps.
The industry moved away from huge, encompassing monolithic applications to distributed applications. Distributed Application Architectures focus more on multiple services and endpoints that comprise the application. Distributed Applications distribute the application load across different services.
Dynamism and intelligence define distributed applications, and its existence acts as the antithesis of monolithic architectures. A number of beneficial features separates the architectures: faster release cycles; app updates in smaller increments; more freedom to make changes to the whole application; layer caching; virtualization; containers; and functions-as-a-service—wherein a function, in a short-lived process, enables the application to communicate and run through the function before the applications destroys it and moves on.
Distributed applications
Distributed architectures provide many different points of analytics for monitoring the flow and its impact on business. The different points of analytics can become a complex management nightmare. Of course, manually sorting through each data point to determine the location of an issue is arduous and time-consuming. Organizations need something more to help them analyze the flow of data, as well as help them monitor and manage project lifecycles, business transactions, and make adjustments to metrics based on business SLAs.
AppDynamics: What It Is, How It Works, & Its Components
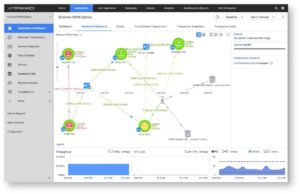
AppDynamics is an application intelligence platform that offers organizations real-time insight into application performance, user experience, and business performance. It’s the tool provides visibility into the flow of data. This could include everything from business transactions to machine learning to application performance. Organizations can capture the experience from the end user down to the data layer and determine the location of issues and bottlenecks in the infrastructure.
Each component works together to provide metrics visibility.
These are the major parts of AppDynamics
The AppDynamics Controller
The first component is the AppDynamics Controller. The controller is a central management server that captures, analyzes, and correlates information for the user. The user can then present the data either via a dashboard style web application from inside the controller or by using an API. For example, if you have your own system for viewing metrics and for pulling information, you can use the API to grab the details from it and then present it into your own style application, if you choose.
The Application Server Agent
The second component is the Application Server Agent. This is where all the business transactions happen and the diagnostics. The agent collects the metrics from the applications and identifies the slow transactions, stalled transactions, or any performance issues at the application layer.
The supported languages are:
- Java
- .NET
- js
- PHP
- Python
- Apache Web Server C
- C++
- Go
- Technologies
The Machine Agent
The third component is the Machine Agent. The machine agent gives the server visibility into the metrics of local processes, the services running, and the resource utilization inside the server. IT teams can see any impacts as well via the machine agent.
The Database Engine
The fourth component is the Database Engine, which is a standalone Java program that collects more performance metrics about the database instance and/or the servers themselves. Application owners can use it to look at the database diagnostics. A database collector controller communicates with the database agent and collects information. All these conversations are one-way conversations if the controller doesn’t talk to the application server agents or the machine agents.
End User Monitoring
The fifth component is the End User Monitoring that provides visibility of the performance of your application from the end user perspective. An additional piece is mobile monitoring, which is done at the mobile monitoring layer. End user monitoring allows engineers to mimic the user experience and journey through the application to find latency. It monitors the whole infrastructure.
These five components give organizations visibility into the metrics on the dashboard which DevOps teams can analyze. They can explore smaller portions of an application to help them understand user experience and business impact. Visibility into each level (code, server, infrastructure, and so forth) help organizations remediate any issue more quickly and more efficiently.
The database metrics show data about queries and the speed of queries for the purpose of optimizing those queries. AppDynamics presents it as tasks—that is, as a way of remediating the bottlenecks in the environment. Again, these metrics provide insight into the user experience, positive and negative, as well as code level impacts, and other things affecting business and the user experience. Organizations can determine reaction and follow-through based on a waterfall-type snapshot that the application provides.
Additionally, in the event of container issues, AppDynamics for Kubernetes exists.
There’s a server metrics dashboard as well. It has four parts:
- CPU
- Memory
- Network
- Availability
The server metrics dashboard provides visibility into the network performance layer. This dashboard, like the previous two dashboards described, measures impact and correlates the collected information as it relates to server infrastructure and application performance.
How AppDynamics Can Help Manage Your Business
Applications are omnipresent in business today. That is why Application Performance Monitoring and Application Performance management are critical. Organizations stand to lose customers and revenue because of performance issues. Real-time insights into user behavior within the application is important. So, too, is advanced analytic capabilities. AppDynamics provides a visual flow of the metrics and data captured to help analyze the complete process of a transaction from submission to final approval.
Lines of business want to understand the impact of performance issues or bottlenecks inside of the network environment. Correcting the issue becomes a priority if user experience is degraded due to performance issues, application bottlenecks, and other latencies. Visibility into the environment, along with the metrics captured help IT teams remediate any issues and bottlenecks more efficiently. The information captured will help correlate applications with business performance and the impact of application performance. The information will help businesses prioritize the facilities it wishes to maintain through reliable and consistent performance.
Issues and impacts will always arise — whether from an application, a server, or code updates. The addition of new features to applications will impact the environment and user experience—sometimes positively and sometimes not. Learning about the specific impact of any issue will help businesses become proactive instead of reactive.
Measuring business impact is one of the key differentiators in the APM space – the ability to look at business transactions and learn specific information about any impact on business. It’s not only about application performance or application monitoring either—it comes down to dollars and cents as well.
